
Em 2026, um computador do tamanho de um livro consegue editar vídeo em 4K, rodar aplicações pesadas e ainda servir modelos de IA localmente — tudo isso consumindo mais ou menos a energia de uma luminária de mesa. O que até pouco tempo atrás era piada virou categoria séria de hardware, e esse texto é um guia prático para entender os principais mini PCs do momento e como transformá-los numa estação de IA que roda offline.
A ideia aqui é didática: mostrar o que mudou, comparar as opções mais relevantes (Apple, Geekom e MinisForum), separar o que é fato do que é marketing e, no fim, deixar o passo a passo para rodar modelos de linguagem na sua própria máquina, sem nuvem e sem assinatura.
De zoação a estação de trabalho
Três anos atrás, mini PC era sinônimo de brinquedo lento. Hoje a história é outra: o Mac Mini M4, por exemplo, consome cerca de 40 W em carga máxima, contra algo perto de 115 W de um Intel Core Ultra 9 em modo turbo. É uma diferença de consumo que muda o jogo para quem deixa a máquina ligada o dia inteiro.
Na prática, os mini PCs atuais entregam:
- desempenho comparável ao de um notebook de configuração intermediária;
- consumo de energia de 2 a 4 vezes menor;
- funcionamento silencioso;
- tamanho pequeno o bastante para caber atrás do monitor.
Apple Mac Mini M4: minimalismo que funciona

A Apple repensou completamente sua abordagem para mini computadores e virou uma das referências do segmento. Segundo a própria empresa, o novo Mac Mini M4 usa 85% menos alumínio e é “20 vezes menor, porém 6 vezes mais rápido que o desktop mais vendido na mesma faixa de preço”. São números de marketing, vale lembrar — mas o consumo baixo é real e mensurável.
A configuração base começa com 16 GB de RAM e SSD de 256 GB (o mínimo de todos os produtos Apple desde 2024). A versão M4 Pro sobe para até 64 GB de RAM e SSD de até 8 TB. O sistema de refrigeração foi redesenhado para o ar passar por todo o chassi, o que praticamente elimina o superaquecimento — mesmo editando vídeo 4K em ferramentas pesadas, a temperatura se mantém confortável.
O ponto fraco é o de sempre na Apple: nada é upgradeável. Subir de 16 GB para 24 GB de RAM custa cerca de US$ 200, e cada 256 GB extras de SSD custam outros US$ 200. Os preços começam em US$ 599 (Mac Mini M4) e US$ 1.399 (M4 Pro). Para quem já vive no ecossistema Apple, ainda é a escolha mais redonda.
Geekom AX8 Pro: o equilíbrio compacto

O Geekom AX8 Pro é um dos mini PCs mais compactos e potentes entre os concorrentes diretos. A configuração gira em torno de AMD Ryzen 9 8945, 32 GB de DDR5 e gráfico Radeon 780M. Em pico, ele puxa cerca de 65 W (com folga para passar dos 54 W nominais), e é aí que ele entrega o máximo em comparação com notebooks. Suporta até quatro monitores simultaneamente.
No quesito jogos, a 1080p em configurações médias, ele roda Cyberpunk 2077 a cerca de 51 FPS e Forza Horizon 5 a 46 FPS — números ótimos para jogos casuais e emulação. A refrigeração dá conta do recado, mas, comparada à da Apple, fica bem mais barulhenta. O consumo de ~45 W nesses cenários continua bem abaixo do dos rivais.
Se comprar pela Amazon, confira o aparelho assim que receber. Vários usuários relataram unidades com defeito de fábrica.
Os preços começam em US$ 529 na versão Ryzen 7 e US$ 749 na Ryzen 9, com possibilidade de adicionar mais memória.
MinisForum: a lenda chinesa com linha completa

Se Geekom e Mac Mini são “cavalos de tração”, a MinisForum é um ambiente de desenvolvimento inteiro. Ela fabrica os próprios mini PCs, do econômico ao monstro com 128 GB de RAM. Vale conhecer a linha:
- UM790 Pro: Ryzen 9 com Radeon 780M e refrigeração muito boa — gráficos impressionantes para o tamanho. O modelo de 16 GB / 512 GB sai por volta de US$ 500.
- AI X1 Pro: AMD Ryzen AI 9 com poder de cálculo otimizado para IA. É o primeiro mini PC desta lista a suportar Copilot+, e ainda traz um Radeon 890 para mais desempenho.
- MS-S1 Max: AMD Ryzen AI Max 395 com 128 GB de LPDDR5. É o tipo de máquina pensada para rodar IA local pesada (e também os jogos mais recentes) com folga.
- G7 Ti: Intel Core i9 + Nvidia GeForce RTX 4070. As melhores marcas de desempenho da lista — praticamente qualquer jogo de 2026 roda com boa qualidade.
- MS-03: Intel Panther Lake com DDR5 e Wi-Fi 7, voltado a pequenas empresas e devs que trabalham em espaços compactos.
O pulo do gato: IA local com Ollama
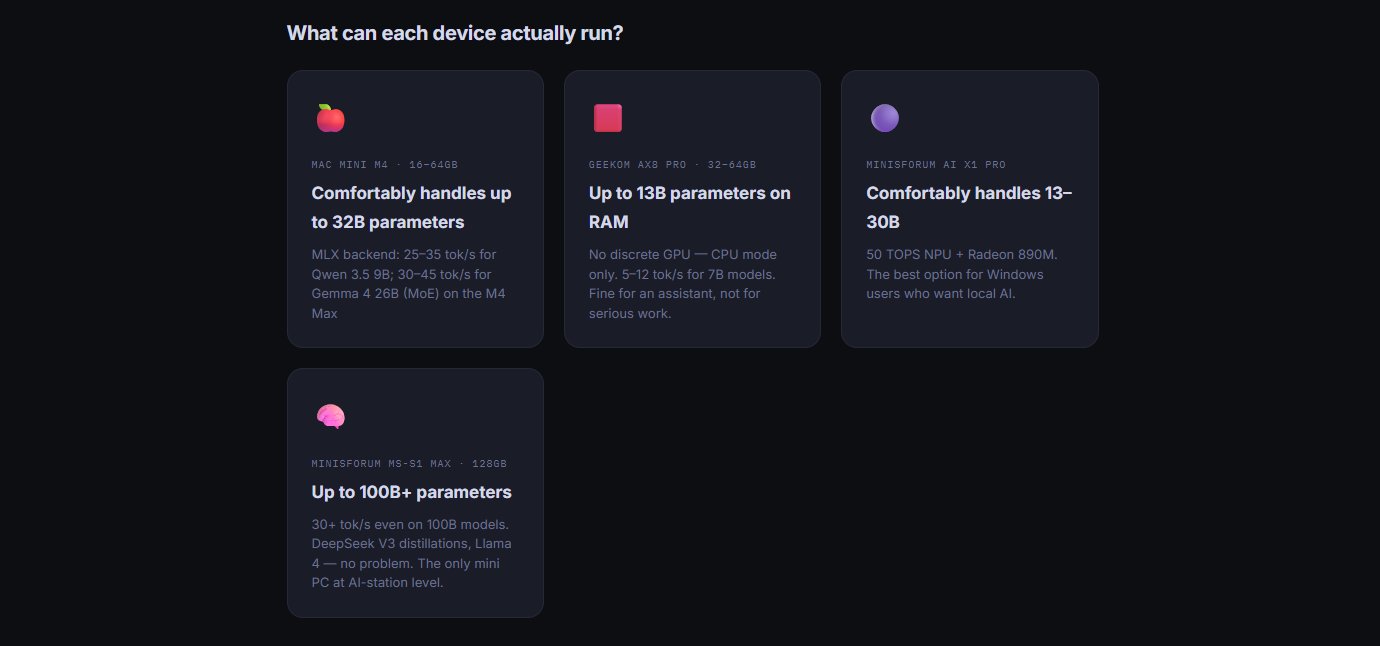
2026 é o ano da IA, e é aqui que o mini PC deixa de ser só um desktop pequeno. O Ollama é uma plataforma open-source que deixa rodar modelos de linguagem (LLMs) localmente, com a mesma facilidade de abrir qualquer outro aplicativo. A grande vantagem é não depender de nuvem nem de assinatura: tudo fica na sua máquina. Desde março de 2026, o Ollama passou a usar o MLX para extrair o máximo de desempenho em hardware Apple.
O detalhe prático que muita gente esquece é escolher um modelo que caiba na RAM do aparelho. Um script simples resolve: ele detecta a memória disponível e sugere um modelo compatível.
#!/usr/bin/env python3
# Detect total RAM and suggest an Ollama model that fits it.
import platform, subprocess
def total_ram_gb() -> int:
system = platform.system()
if system == "Darwin": # macOS
out = subprocess.run(["sysctl", "-n", "hw.memsize"],
capture_output=True, text=True).stdout
return int(out) // 1024 ** 3
if system == "Linux":
with open("/proc/meminfo") as f:
kb = int(f.readline().split()[1])
return kb // 1024 ** 2
out = subprocess.run(["wmic", "ComputerSystem", "get", "TotalPhysicalMemory"],
capture_output=True, text=True).stdout.split()[-1]
return int(out) // 1024 ** 3
def suggest(ram: int) -> str:
if ram >= 64:
return "qwen3:32b" # heavy reasoning / code
if ram >= 32:
return "qwen3:14b" # great all-rounder
if ram >= 16:
return "llama3.2:8b" # base Mac Mini M4
return "gemma3:4b" # tight on memory
ram = total_ram_gb()
print(f"RAM: {ram} GB -> ollama pull {suggest(ram)}")Com o modelo escolhido, o próximo passo é subir o servidor e uma interface de chat. O script abaixo sobe o Ollama e a Open WebUI (uma interface estilo ChatGPT) via Docker, tudo local.
#!/usr/bin/env bash
# Local AI stack: Ollama (model server) + Open WebUI (chat interface).
set -e
MODEL="qwen3:14b" # pick whatever fits your RAM
# 1. Start Ollama in the background (install it from https://ollama.com)
ollama serve >/tmp/ollama.log 2>&1 &
sleep 2
# 2. Pull the model once
ollama list | grep -q "$MODEL" || ollama pull "$MODEL"
# 3. Run Open WebUI in Docker, pointing to the local Ollama
docker run -d --name open-webui --restart unless-stopped \
-p 3000:8080 \
-e OLLAMA_BASE_URL="http://host.docker.internal:11434" \
-v open-webui:/app/backend/data \
ghcr.io/open-webui/open-webui:main
echo "Open http://localhost:3000 — everything runs locally, no cloud."Pontos de atenção
Antes de sair comprando, vale calibrar a expectativa:
- Boa parte das specs de 2026 ainda é movel. Plataformas como Intel Panther Lake, RTX 4070 em mini PC, Ryzen AI Max 395 e o suporte a Copilot+ aparecem em anúncios e roadmaps; confira disponibilidade e números oficiais antes de decidir.
- Os números da Apple são marketing. “20x menor, 6x mais rápido, 85% menos alumínio” vem da própria empresa — úteis como referência, não como benchmark independente.
- Preços e FPS são de referência. Variam por região, configuração e título testado. Use como ordem de grandeza.
- RAM e SSD soldados. No Mac Mini, decida a configuração no ato da compra: não dá para ampliar depois, e os upgrades de fábrica são caros.
- Controle de qualidade. Em mini PCs comprados em marketplaces, teste a unidade assim que chegar — relatos de defeito de fábrica não são raros.
- Modelo tem que caber na RAM. Rodar um LLM grande demais para a memória derruba o desempenho; siga a regra do script e suba o tamanho do modelo aos poucos.
Conclusão
Comprar um mini PC em 2026 deixou de ser comprar “um computador pequeno” e passou a ser, na prática, montar um agente de IA próprio — que trabalha localmente via Ollama e companhia, sem assinatura, sem custo de armazenamento na nuvem e com todas as consultas ficando só na sua máquina.
A escolha continua sendo de encaixe, não de hype: quem vive no ecossistema Apple ganha com o Mac Mini M4; quem quer equilíbrio compacto olha o Geekom; quem precisa de poder bruto e RAM enorme para IA local vai de MinisForum. De olho daqui para frente: o que era diferencial de servidor — rodar modelos de verdade, em casa, gastando energia de luminária — agora cabe atrás do monitor. 🚀