O ECC — Everything Claude Code viralizou no GitHub e já passa de 197 mil stars. Mas a maioria das matérias para por aí: cita os números, lista os agentes e skills e não mostra como isso muda a sua terça-feira mantendo um site no ar. Esse post é diferente — vou usar um cenário concreto (um site real, com backend, formulário e deploy) e mostrar onde o ECC entra em cada momento. 🧠💻
De onde veio o projeto
Affaan Mustafa venceu o Anthropic x Forum Ventures Hackathon em Nova York, competindo contra mais de 100 times. Em 8 horas, ele e seu parceiro construíram um produto funcional — o zenith.chat — usando Claude Code, e levaram US$ 15.000 em créditos de API. 🏆
O detalhe que importa: Affaan não chegou ao hackathon com um chat em branco. Ele chegou com um ambiente de Claude Code lapidado em mais de 10 meses de uso diário real — agentes especializados, skills por domínio, memória entre sessões, hooks automáticos, regras por linguagem. Depois do evento, ele abriu tudo como open source. Nasceu o ECC: basicamente a "config de trabalho" de um dev que usa IA todos os dias, empacotada para você instalar a sua.
O problema que ele resolve (de verdade)
Imagine que você mantém um site sozinho ou em time pequeno: um blog com backend, formulário de contato, área de admin, deploy próprio. Se você usa IA pra programar isso, esses momentos vão soar familiares:
- São 18h, você está há uma hora pedindo ajustes numa página, e do nada o Claude sugere reescrever um arquivo que vocês já tinham acertado três mensagens atrás — o contexto apodreceu no meio da sessão.
- Você pede "cria o endpoint de newsletter" e vem o código sem validação de e-mail, sem teste, ignorando o padrão de resposta que o resto da sua API já usa.
- Você abre o projeto no Cursor no notebook e no Claude Code no desktop — e tem que explicar as mesmas convenções de novo em cada um.
- Você fecha o editor no meio de uma feature na sexta. Na segunda, gasta 15 minutos só relembrando onde tinha parado e o que faltava.
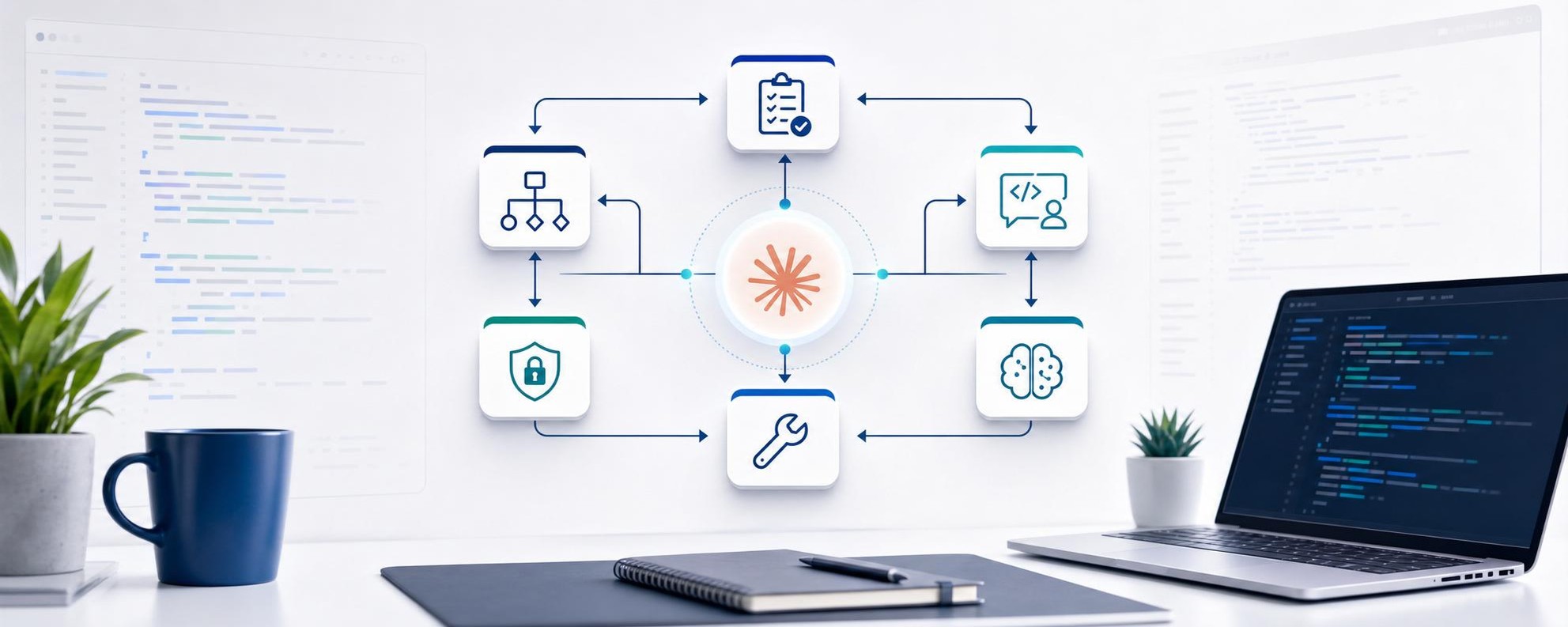
O ECC ataca exatamente esses pontos. Ele é uma camada de operação por cima das ferramentas de IA: Claude Code, Cursor, Codex, OpenCode, Gemini, Zed e GitHub Copilot passam a usar os mesmos agentes, skills, regras e hooks. Você configura uma vez, e o comportamento te segue. 🛠️
Como instalar: escolha um caminho só
O aviso mais importante da documentação: não misture os métodos de instalação. Todos instalam o mesmo conteúdo — se você usar dois, vai ficar tudo duplicado e brigando entre si.
Antes de tudo: onde cada coisa roda e onde cada coisa fica
Essa é a parte que mais confunde quem está começando, então vamos por partes. Existem dois lugares diferentes envolvidos, e quase nada do que você vai rodar mexe no seu projeto:
- A instalação do ECC é global. Os agentes, skills, regras e hooks são instalados na pasta
~/.claude/— a configuração do Claude Code no seu usuário (o~é a sua pasta pessoal:/Users/seunomeno Mac,C:\Users\seunomeno Windows). Você faz isso uma única vez e vale pra todos os projetos da máquina. Não vai nada disso pra dentro do site. - Só um arquivo mora no projeto: o
.claude/CLAUDE.md, que descreve a stack daquele site específico (veremos mais abaixo). Esse sim entra no git e acompanha o projeto.
Agora, comando por comando, onde você digita cada coisa:
- Os comandos que começam com
/(tipo/plugin install) → você digita dentro do Claude Code, na própria conversa. Tanto faz qual projeto está aberto — eles configuram o ECC globalmente. - O
git clone→ serve só pra baixar os arquivos do ECC pra você copiar de lá. A pasta onde você clona não importa e pode ser apagada depois. Use uma pasta temporária fora do seu projeto (ex.:/tmpou~/Downloads). - Os comandos
cp,npm installe./install.sh→ você roda dentro dessa pasta que acabou de clonar (por isso ocd everything-claude-codeantes). Eles copiam os arquivos de lá pra~/.claude/.
Visualmente, depois de instalar, fica assim — repare que são dois mundos separados:
# 1) GLOBAL — a "máquina" do ECC, instalada uma vez no seu usuário
~/.claude/
├── agents/ ← os 63 agentes
├── skills/ ← as 249 skills
├── rules/ecc/ ← as regras que você copiou (common, python...)
└── settings.json ← configuração global (modelo, hooks, etc.)
# 2) NO SEU PROJETO — só o CLAUDE.md, versionado junto com o site
~/Developer/meu-site/
├── .claude/
│ └── CLAUDE.md ← descreve a stack DESTE projeto
├── src/
└── ...Resumindo numa frase: o "motor" (agentes, skills, regras, hooks) é global em ~/.claude/; só o CLAUDE.md, que descreve a stack do projeto, fica dentro do projeto. O git clone é apenas um download temporário — depois de copiar o que precisa, pode apagar a pasta. 📁
Caminho 1 — Plugin (recomendado para Claude Code)
Dentro do Claude Code, rode:
/plugin marketplace add https://github.com/affaan-m/ECC
/plugin install ecc@eccIsso instala comandos, agentes e skills automaticamente. Mas as regras precisam ser copiadas à mão — o plugin não pode distribuí-las. Copie só as linguagens que você realmente usa no site (não adianta puxar Go se seu backend é Python):
# Rode isto numa pasta QUALQUER fora do seu projeto (ex.: /tmp)
cd /tmp
git clone https://github.com/affaan-m/everything-claude-code.git
cd everything-claude-code
mkdir -p ~/.claude/rules/ecc
cp -R rules/common ~/.claude/rules/ecc/
# No exemplo deste post: site com backend Python e frontend TypeScript
cp -R rules/python ~/.claude/rules/ecc/
cp -R rules/typescript ~/.claude/rules/ecc/
# Pronto. A pasta clonada já cumpriu o papel e pode ser apagada:
cd ~ && rm -rf /tmp/everything-claude-codeCaminho 2 — Instalação manual completa
git clone https://github.com/affaan-m/everything-claude-code.git
cd everything-claude-code
npm install
./install.sh --profile fullNo Windows: .\install.ps1 --profile full
Caminho 3 — Instalação mínima (sem hooks)
./install.sh --profile minimal --target claudeÉ por onde eu recomendaria começar: só skills e agentes, sem as automações de hook. Você sente o ganho sem que nada rode "sozinho" antes de você entender o que é cada coisa. Depois liga o resto.
O que cada parte faz na prática
Agentes: quando você quer foco profundo numa coisa só
Agentes são subagentes especializados. Você chama um quando a tarefa pede atenção dedicada — não pra qualquer pergunta. No dia a dia de um site, os que mais aparecem:
- planner — quebra "adicionar comentários no blog" em subtarefas antes de você sair codando
- code-reviewer — revisa qualidade, segurança e manutenibilidade antes do merge
- tdd-guide — conduz o ciclo Red-Green-Refactor e cobra 80%+ de cobertura
- architect — quando a decisão é "uso fila ou rodo isso síncrono mesmo?"
- security-reviewer — olha o formulário de contato atrás de XSS, o admin atrás de falha de auth
- build-error-resolver — quando o deploy quebrou e o log não ajuda
- python-reviewer, go-reviewer, typescript-reviewer — revisão específica por linguagem
Você invoca assim no Claude Code: /ecc:plan "adicionar comentários no blog" — ou chamando o agente direto pelo nome.
Skills: o jeito principal de trabalhar
Skills são fluxos reutilizáveis por domínio. Em vez de digitar o mesmo prompt enorme toda vez ("escreve o teste primeiro, depois implementa, roda o lint, confere cobertura..."), você chama uma skill que já embute esse fluxo com os critérios certos. As que valem no dia a dia de um site:
- tdd-workflow — ciclo Red-Green-Improve com exigência de cobertura mínima
- verification-loop — roda build, testes, lint, typecheck e segurança em sequência antes de você dar push
- backend-patterns — padrões de API, cache e banco de dados
- django-patterns, springboot-patterns, laravel-patterns — específicos por framework
- frontend-patterns — React e Next.js
- docker-patterns — Compose, rede, segurança de container (útil quando seu site sobe em container)
- continuous-learning-v2 — extrai padrões do histórico da sessão e salva como instincts
- mle-workflow — pra quem tem ML em produção: contratos de dados, evals, deploy
Hooks: as automações que rodam sem você pedir
Hooks disparam sozinhos em resposta a eventos. É aqui que o "ambiente" deixa de ser teoria. Casos concretos com hooks ligados:
- Você salva um componente
.ts→ o hook roda o formatter e o typecheck na hora, e você descobre o erro de tipo antes do deploy, não depois. - Você fecha a sessão no meio da feature de newsletter → o hook salva o contexto pra próxima abrir de onde parou.
- A IA tenta editar
.ruff.tomlsó pra calar um aviso do linter → o hook bloqueia e força corrigir o código de verdade. - Alguém tenta commitar com
--no-verifypulando os hooks de git → bloqueado. - Um prompt tenta vazar uma chave de API no texto → o hook detecta e barra antes de enviar.
Para ajustar o comportamento por variável de ambiente — por exemplo, desligar um hook chato sem desligar todos:
# Perfis disponíveis: minimal, standard, strict
export ECC_HOOK_PROFILE=standard
# Desativar hooks específicos pelo nome
export ECC_DISABLED_HOOKS="pre:bash:tmux-reminder,post:edit:typecheck"
# Desativar carregamento de contexto no início da sessão
export ECC_SESSION_START_CONTEXT=offRegras: o que sempre vale, sem repetir no prompt
Regras são arquivos markdown que o Claude lê no início de cada sessão. São as combinações que você cansou de repetir:
- Fluxo de git e formato de commit do seu projeto
- TDD obrigatório com cobertura mínima de 80%
- Verificação de segurança antes de qualquer deploy
- Convenções por linguagem: PEP 8 no Python, idiomas do Go, strict mode no TypeScript
Fluxo real: adicionando comentários ao blog
Junta tudo num exemplo concreto. Você quer adicionar comentários nos posts do seu blog. Como fica com o ECC:
# 1. Planejar antes de codar
/ecc:plan "adicionar comentários nos posts: endpoint, validação e moderação"
# 2. Ciclo TDD para o endpoint
# → Teste que falha: POST de comentário vazio deve dar 400 (RED)
# → Implementar o mínimo para passar (GREEN)
# → Refatorar a validação (IMPROVE)
# → Conferir cobertura mínima de 80%
# 3. Review antes de mergear
/code-review
# 4. Scan de segurança (comentário é input do público → XSS, spam)
/security-scanSão 18h de novo e o deploy quebrou. Em vez de caçar no log na mão:
/build-fix
# O agente lê o output do erro, confere o toolchain
# (package.json, requirements.txt etc.), sugere a correção
# e valida rodando o build de novoResolveu algo não óbvio? Salva o aprendizado pra não repetir o erro daqui a um mês:
/learn "moderação de comentários e proteção contra spam"
/instinct-status # ver o que foi salvo
/instinct-export > padroes.json # exportar pra compartilhar com o timeConfigurar o projeto: o arquivo CLAUDE.md
Cada projeto pode ter um .claude/CLAUDE.md que o Claude lê ao iniciar. É onde você declara a stack do site, as skills ativas, os agentes e as regras específicas. O ECC já vem com exemplos prontos pros cenários comuns: Next.js + Supabase, Go microservice, Django API, Laravel e Rust com Axum.
Um exemplo realista pra um site com frontend Next.js e backend Django:
## Stack
- Frontend: Next.js 16+ com React 19 e TypeScript strict
- Backend: Django 5.0 com DRF e PostgreSQL 15+
- Tarefas async (envio de e-mail, etc.): Celery
## Exigências de teste
- Frontend: 80%+ de cobertura com Jest
- Backend: 85%+ com pytest
- E2E: Playwright nos fluxos críticos (login, formulário de contato)
## Segurança
- Auth: OAuth2 + JWT
- Secrets: nunca no código, sempre em variáveis de ambienteCom esse arquivo no lugar, você para de digitar "lembra que a gente usa pytest e não pode pôr secret no código" toda sessão. O Claude já sabe. 📂
AgentShield: auditoria de segurança das suas configs de IA
Aqui tem um ponto que pouca gente pensa. Quando você tem agentes rodando comandos, hooks automáticos e MCPs conectados, a superfície de ataque deixa de ser só o código do site — passa a incluir a própria configuração da IA. O AgentShield escaneia exatamente isso. 🔐
Ele verifica seus arquivos CLAUDE.md, settings.json, configs de MCP, hooks, agents e skills. Detecta 14 padrões de secrets vazados (aquela chave que você colou "só pra testar" e esqueceu), permissões excessivas, riscos de injeção em hooks e MCPs mal configurados. São 1.282 testes e 102 regras de análise estática por trás.
# Scan rápido, sem instalar nada
npx ecc-agentshield scan
# Corrigir automaticamente o que é seguro corrigir
npx ecc-agentshield scan --fix
# Modo profundo: 3 agentes Opus em pipeline red-team / blue-team / auditoria
npx ecc-agentshield scan --opus --stream
# Gerar relatório HTML pra revisar com calma
npx ecc-agentshield scan --format html > relatorio.html
# Rodar no CI (sai com código 2 se achar algo crítico → quebra o pipeline)
npx ecc-agentshield scan --format jsonOu direto dentro do Claude Code: /security-scan.
O modo --opus é o mais interessante: três agentes Claude Opus em sequência — um ataca (red-team), outro avalia as defesas (blue-team) e o terceiro organiza os riscos. O resultado vem com notas de A a F por categoria, tipo um boletim da sua config. 🤯
Memória entre sessões: a IA que não esquece onde parou
Esse é, na minha opinião, o ganho mais palpável no dia a dia. Os hooks salvam o estado ao final de cada sessão e restauram no início da próxima.
Na prática: você está no meio da feature de newsletter, dá 19h, fecha tudo. No dia seguinte abre o Claude Code e ele sabe onde parou — qual era o plano, o que já ficou pronto, o que falta. Acabaram os 15 minutos de "deixa eu reler o diff pra lembrar o que eu estava fazendo". 🧠🔁
# Ver sessões anteriores
/sessions
# Ajustar o limite de caracteres carregados (sessão grande = mais contexto)
export ECC_SESSION_START_MAX_CHARS=4000
# Desativar, se você prefere começar limpo todo dia
export ECC_SESSION_START_CONTEXT=offControle de custo e contexto
Usar IA todo dia pesa no bolso se você deixar tudo no Opus. O ECC traz controles explícitos. A regra de ouro: Sonnet para 80% das tarefas (60% mais barato que Opus), Opus só pro raciocínio profundo de verdade.
/cost # ver quanto você já gastou na sessão
/model sonnet # ajuste de CSS, endpoint simples, a maioria das tarefas
/model opus # decisão de arquitetura, bug cabeludo
/compact # compactar o contexto num ponto de parada lógicoNo ~/.claude/settings.json global, dá pra deixar isso como padrão:
{
"model": "sonnet",
"env": {
"MAX_THINKING_TOKENS": "10000",
"CLAUDE_AUTOCOMPACT_PCT_OVERRIDE": "50",
"CLAUDE_CODE_SUBAGENT_MODEL": "haiku"
}
}Baixar o thinking para 10.000 tokens corta cerca de 70% do custo oculto de raciocínio. Pôr os subagentes em Haiku economiza bastante nas tarefas simples de delegação — aquele agente que só lê um arquivo e devolve um resumo não precisa de Opus.
Funciona em outras ferramentas além do Claude Code?
Sim — e essa é uma das propostas centrais. Você configura num lugar e usa em todas. Útil pra quem alterna entre desktop, notebook e um editor diferente no trabalho:
- Cursor:
./install.sh --target cursor typescript python— tem 15 eventos de hook (mais que o próprio Claude Code) - Codex:
bash scripts/sync-ecc-to-codex.sh— carrega oAGENTS.mdautomaticamente - OpenCode:
npm install ecc-universale adiciona aoopencode.json - GitHub Copilot (VS Code): zero instalação — os arquivos
.github/copilot-instructions.mde.github/prompts/*.prompt.mdsão detectados automaticamente pelo Copilot Chat - Zed:
./install.sh --profile minimal --target zed
Para quem faz sentido — e para quem não faz
Vale o senso de realidade: 63 agentes, 249 skills e hooks automáticos são exagero pra um site estático ou pra quem está começando agora com IA. Você vai passar mais tempo entendendo a config do que economizando com ela. Comece pelo perfil mínimo.
O ECC compensa quando você:
- Usa IA pra programar quase todo dia e quer consistência entre as sessões
- Trabalha em time e quer que todo mundo use a IA do mesmo jeito no projeto
- Alterna entre ferramentas (Claude Code, Cursor, Copilot) e está cansado de reconfigurar
- Já perdeu tempo com contexto que apodreceu no meio de uma sessão longa
- Quer que a IA siga TDD, respeite os padrões do projeto e escaneie segurança sem você ter que lembrar de pedir toda vez
Conclusão
O que o ECC representa não é só um repositório com muitas stars. É uma virada de chave sobre como usar IA pra programar: não como um chatbot que você interroga do zero toda vez, mas como uma infraestrutura de desenvolvimento com processo, memória, segurança e especialização por tarefa. 🏗️🚀
O prêmio no hackathon foi só o gatilho. O crescimento explosivo depois mostra que a comunidade chegou na mesma pergunta que Affaan respondeu nos seus 10 meses de uso diário: como fazer a IA trabalhar de forma estruturada dentro de projetos reais, e não só responder bem a um prompt isolado?
A resposta não é um prompt melhor. É um ambiente melhor. ⚡
🔗 Repositório: github.com/affaan-m/everything-claude-code