
WSGI e ASGI definem como aplicações Python conversam com servidores, moldando o tratamento de requisições, a concorrência e a escalabilidade. Essas duas interfaces explicam por que aplicações tradicionais em Django se comportam de modo diferente de frameworks assíncronos como FastAPI. No centro do tema está a forma como o servidor chama o código Python e como o código lida com operações de entrada e saída. A distinção entre execução síncrona e assíncrona impacta latência, uso de recursos e suporte a conexões de longa duração. Entender esse contraste oferece base sólida para escolher tecnologias e configurar implantações.
O caminho de uma requisição passa por várias camadas até chegar ao código da aplicação. Primeiro o navegador envia a requisição, um servidor HTTP lida com conexões e repassa para um servidor de aplicação. Em seguida, a aplicação Python recebe os dados por uma interface padronizada e devolve a resposta. Essa interface é o contrato que define formato, ciclo de vida e responsabilidades em cada etapa. Nesse cenário, WSGI e ASGI surgem como padrões que resolvem como o servidor chama o aplicativo.
O problema: como o servidor conversa com o Python
Sem um contrato comum, cada servidor e cada framework precisaria de integrações próprias, gerando incompatibilidades. Para evitar isso, cria-se uma interface que padroniza o “ponto de entrada” da aplicação web em Python. Essa interface define o que é enviado para o aplicativo e o que deve ser devolvido ao servidor. Com isso, um servidor genérico consegue executar qualquer app que respeite o contrato acordado. Esse acoplamento fraco sustentou a evolução do ecossistema web em Python.
Nesse fluxo, o servidor HTTP fokado em rede aceita conexões, aplica regras de roteamento e repassa a carga para o servidor de aplicação. O servidor de aplicação, por sua vez, instancia processos ou threads e executa o código Python. O aplicativo responde sempre seguindo o protocolo previsto pela interface. A vantagem é que a aplicação não precisa conhecer detalhes do servidor. Por fim, a resposta é enviada de volta até o navegador pelo mesmo caminho inverso.
WSGI: o contrato síncrono que consolidou a Web em Python
WSGI (Web Server Gateway Interface) padroniza a comunicação entre servidores e aplicações Python em um modelo totalmente síncrono. O contrato é simples: a aplicação se comporta como uma função que recebe um dicionário de ambiente e um callback para iniciar a resposta. O retorno deve ser um iterável de bytes, representando o corpo da resposta. Essa simplicidade permitiu compatibilidade ampla entre servidores como Gunicorn e frameworks como Django e Flask. Durante anos, esse padrão atendeu bem à maior parte das aplicações web.
O exemplo a seguir apresenta uma aplicação WSGI mínima e robusta, já com tratamento de erros. O código mostra como extrair método e caminho, definir cabeçalhos e retornar JSON. Esse formato é o que um servidor WSGI chamará a cada requisição recebida. Trata-se de um “hello world” profissional, com mensagens claras e status adequados.
import json
from typing import Callable, Iterable, Tuple, Dict, Any
# Assinatura WSGI: (environ, start_response) -> Iterable[bytes]
def application(environ: Dict[str, Any], start_response: Callable[[str, list[Tuple[str, str]]], None]) -> Iterable[bytes]:
"""
Aplicação WSGI mínima.
- environ: informações da requisição (método, caminho, cabeçalhos).
- start_response: função para iniciar a resposta (status e cabeçalhos).
- retorno: iterável de bytes com o corpo da resposta.
"""
try:
metodo = environ.get("REQUEST_METHOD", "GET")
caminho = environ.get("PATH_INFO", "/")
status = "200 OK"
cabecalhos = [("Content-Type", "application/json; charset=utf-8")]
corpo = json.dumps({"metodo": metodo, "caminho": caminho}).encode("utf-8")
except Exception as erro:
status = "500 Internal Server Error"
cabecalhos = [("Content-Type", "text/plain; charset=utf-8")]
corpo = f"Erro interno: {erro}".encode("utf-8")
# Inicia a resposta e retorna o corpo como iterável
start_response(status, cabecalhos)
return [corpo]Limitações do WSGI em aplicações modernas
O modelo de execução síncrona presume que cada requisição é processada do início ao fim por um worker sem pausa. Se o código bloqueia, o worker fica indisponível até terminar, aumentando a latência e reduzindo a capacidade de atendimento simultâneo. Esse bloqueio ocorre em chamadas como acesso a disco, consultas de rede e atrasos artificiais com time.sleep. Para contornar, servidores criam mais processos ou threads, elevando consumo de memória. Esse desenho funciona, mas escala com mais custo em cenários de alta concorrência ou conexões longas.
O trecho abaixo ilustra o bloqueio clássico em código síncrono, suficiente para impedir o worker de atender novas requisições por alguns segundos. Esse padrão é aceitável para cargas pequenas, porém degrada sob picos de tráfego. Além disso, recursos como WebSockets e transmissões contínuas não fazem parte do contrato WSGI. Em consequência, soluções modernas buscaram outro caminho. Surge então a interface assíncrona.
import time
from typing import Callable, Iterable, Tuple, Dict, Any
def application(environ: Dict[str, Any], start_response: Callable[[str, list[Tuple[str, str]]], None]) -> Iterable[bytes]:
# Simula operação bloqueante (ex.: chamada externa lenta)
time.sleep(5) # durante 5s, o worker não atende outra requisição
start_response("200 OK", [("Content-Type", "text/plain; charset=utf-8")])
return [b"Resposta apos espera bloqueante"]ASGI: o contrato assíncrono para a Web em tempo real
ASGI (Asynchronous Server Gateway Interface) evolui o contrato para suportar execução não bloqueante, múltiplos protocolos e conexões duradouras. Em vez de uma função síncrona, a aplicação expõe uma função assíncrona que conversa por eventos com o servidor. O servidor envia eventos de entrada e a aplicação devolve eventos de saída, permitindo fluxos contínuos. Esse desenho suporta HTTP, WebSockets e ciclo de vida da aplicação, numa única interface. Um único worker pode coordenar muitas tarefas concorrentes dentro de um event loop.
O exemplo a seguir apresenta uma aplicação ASGI mínima com suporte a HTTP e WebSocket. A função lê o tipo de escopo, prepara cabeçalhos e responde com corpo JSON ou ecoa mensagens pelo socket. A estrutura de eventos é explícita, deixando claro quando enviar início de resposta e blocos de corpo. Esse mecanismo viabiliza streaming e comunicação bidirecional. A abordagem favorece baixa latência sob alta concorrência.
import json
from typing import Any, Dict
# Assinatura ASGI: async app(scope, receive, send)
async def app(scope: Dict[str, Any], receive, send) -> None:
tipo = scope["type"]
if tipo == "http":
# Corpo simples em JSON
corpo = json.dumps({"mensagem": "olá, mundo", "caminho": scope.get("path", "/")}).encode("utf-8")
await send({
"type": "http.response.start",
"status": 200,
"headers": [(b"content-type", b"application/json; charset=utf-8")],
})
await send({"type": "http.response.body", "body": corpo})
elif tipo == "websocket":
# Aceita a conexão e ecoa mensagens em maiúsculas
await send({"type": "websocket.accept"})
while True:
evento = await receive()
if evento["type"] == "websocket.receive":
texto = evento.get("text") or ""
await send({"type": "websocket.send", "text": texto.upper()})
elif evento["type"] == "websocket.disconnect":
breakComparando arquiteturas: WSGI e ASGI na prática
No modelo WSGI, cada requisição ocupa um worker até a conclusão, e componentes bloqueantes impedem atendimento paralelo no mesmo worker. Esse desenho incentiva aumentar processos e threads para ganhar vazão, o que eleva memória e troca de contexto. A previsibilidade é alta, com fluxo simples do tipo requisição–processamento–resposta. Entretanto, conexões longas e streaming forçam contornos ou componentes adicionais. O resultado é bom para páginas clássicas e APIs simples, porém menos eficiente para interações em tempo real.
No modelo ASGI, um worker coordena várias corrotinas dentro de um event loop, alternando entre tarefas enquanto esperam I/O. Isso reduz o número de workers necessários e melhora a utilização da CPU quando a carga é dominada por operações de rede. O suporte nativo a WebSockets e a streaming simplifica serviços modernos, como chat, notificações e SSE. As tarefas não bloqueantes compartilham o loop, enquanto o código bloqueante deve ser isolado em threads. A abordagem entrega menor latência sob concorrência elevada com consumo de recursos mais contido.
Django: por que a arquitetura é chamada de híbrida
Django nasceu inteiramente baseado em WSGI e adotou ASGI mais tarde, mantendo grande parte do núcleo síncrono por compatibilidade. Componentes como ORM, middleware e renderização de templates ainda seguem o modelo bloqueante na maioria dos casos. Para executar em ambiente ASGI, o framework usa pontes internas que convertem chamadas síncronas para assíncronas. Esse “vai e volta” preserva o ecossistema maduro e a previsibilidade do comportamento. Por isso a descrição de arquitetura híbrida é apropriada.
O exemplo abaixo demonstra uma view assíncrona que consulta o banco por meio de uma ponte síncrono→assíncrono. A estratégia evita bloquear o event loop durante a interação com o ORM. Esse padrão permite adoção gradual de recursos assíncronos sem reescrever toda a aplicação. O resultado combina compatibilidade com ganhos em endpoints que não tocam o ORM. A organização do código deixa claro onde ocorre a transição de contexto.
# views.py (Django)
from typing import List, Dict, Any
from django.http import JsonResponse
from asgiref.sync import sync_to_async
from .models import Produto
@sync_to_async
def consultar_produtos(limit: int = 5) -> List[Dict[str, Any]]:
# Consulta síncrona via ORM (bloqueante), isolada pela ponte
return list(Produto.objects.values("id", "nome")[:limit])
async def listar_produtos(request):
itens = await consultar_produtos(5)
return JsonResponse({"itens": itens})FastAPI: assíncrono desde a origem
FastAPI foi projetado sobre um núcleo assíncrono, com roteamento e middlewares preparados para corrotinas. O framework adota tipagem estática com anotações, facilitando validação de dados e geração de documentação. Ao lidar com funções síncronas, a execução ocorre em um thread pool para não bloquear o event loop. Essa decisão mantém a experiência assíncrona mesmo com bibliotecas legadas. O comportamento padrão favorece concorrência elevada em operações de I/O.
O exemplo a seguir mostra uma rota assíncrona não bloqueante e outra síncrona que será isolada automaticamente. A combinação evidencia como o framework acomoda códigos de naturezas diferentes. A rota assíncrona usa asyncio.sleep para simular espera sem bloquear. A rota síncrona usa time.sleep, ilustrando trabalho que vai para threads. A resposta permanece consistente para o cliente em ambos os casos.
# app.py (FastAPI)
from typing import Dict
import asyncio
import time
from fastapi import FastAPI
app = FastAPI()
@app.get("/io-assincrono")
async def io_assincrono() -> Dict[str, str]:
# Espera não bloqueante (I/O simulado)
await asyncio.sleep(0.5)
return {"status": "ok", "modo": "async"}
@app.get("/tarefa-sincrona")
def tarefa_sincrona() -> Dict[str, str]:
# Bloqueia a thread atual; o servidor despacha para um thread pool
time.sleep(2)
return {"status": "ok", "modo": "sync"}Bancos de dados: o fator que muda tudo
Bancos de dados influenciam diretamente o ganho de desempenho com código assíncrono. ORMs e drivers tradicionais operam de forma bloqueante, exigindo ponte para threads sob ASGI. Esse desvio impede bloqueio do loop, mas ainda consome threads e pode limitar a escalabilidade sob carga intensa. Drivers e ORMs com suporte nativo a assíncrono removem a etapa do thread pool. Assim, toda a cadeia permanece não bloqueante, do servidor até a consulta.
O trecho a seguir ilustra uma configuração de SQLAlchemy assíncrono com driver adequado, incluindo definição de modelo e consulta. Nessa abordagem, a sessão e as operações do banco são corrotinas, preservando o fluxo async de ponta a ponta. O uso de tipos e limites claros evita surpresas de desempenho. O exemplo supõe um banco compatível, como PostgreSQL com driver assíncrono. A organização mantém a aplicação responsiva sob alta concorrência de consultas.
# db_async.py (SQLAlchemy assíncrono)
from typing import List, Dict
import sqlalchemy as sa
from sqlalchemy.orm import declarative_base, Mapped, mapped_column
from sqlalchemy.ext.asyncio import AsyncSession, create_async_engine, async_sessionmaker
Base = declarative_base()
class Usuario(Base):
__tablename__ = "usuarios"
id: Mapped[int] = mapped_column(primary_key=True)
nome: Mapped[str] = mapped_column(sa.String(100), nullable=False)
# Driver assíncrono (ex.: asyncpg para PostgreSQL)
engine = create_async_engine("postgresql+asyncpg://usuario:senha@localhost:5432/app", echo=False)
Session = async_sessionmaker(engine, class_=AsyncSession, expire_on_commit=False)
async def listar_usuarios(limite: int = 10) -> List[Dict[str, str]]:
async with Session() as sessao:
resultado = await sessao.execute(sa.select(Usuario).limit(limite))
usuarios = resultado.scalars().all()
return [{"id": u.id, "nome": u.nome} for u in usuarios]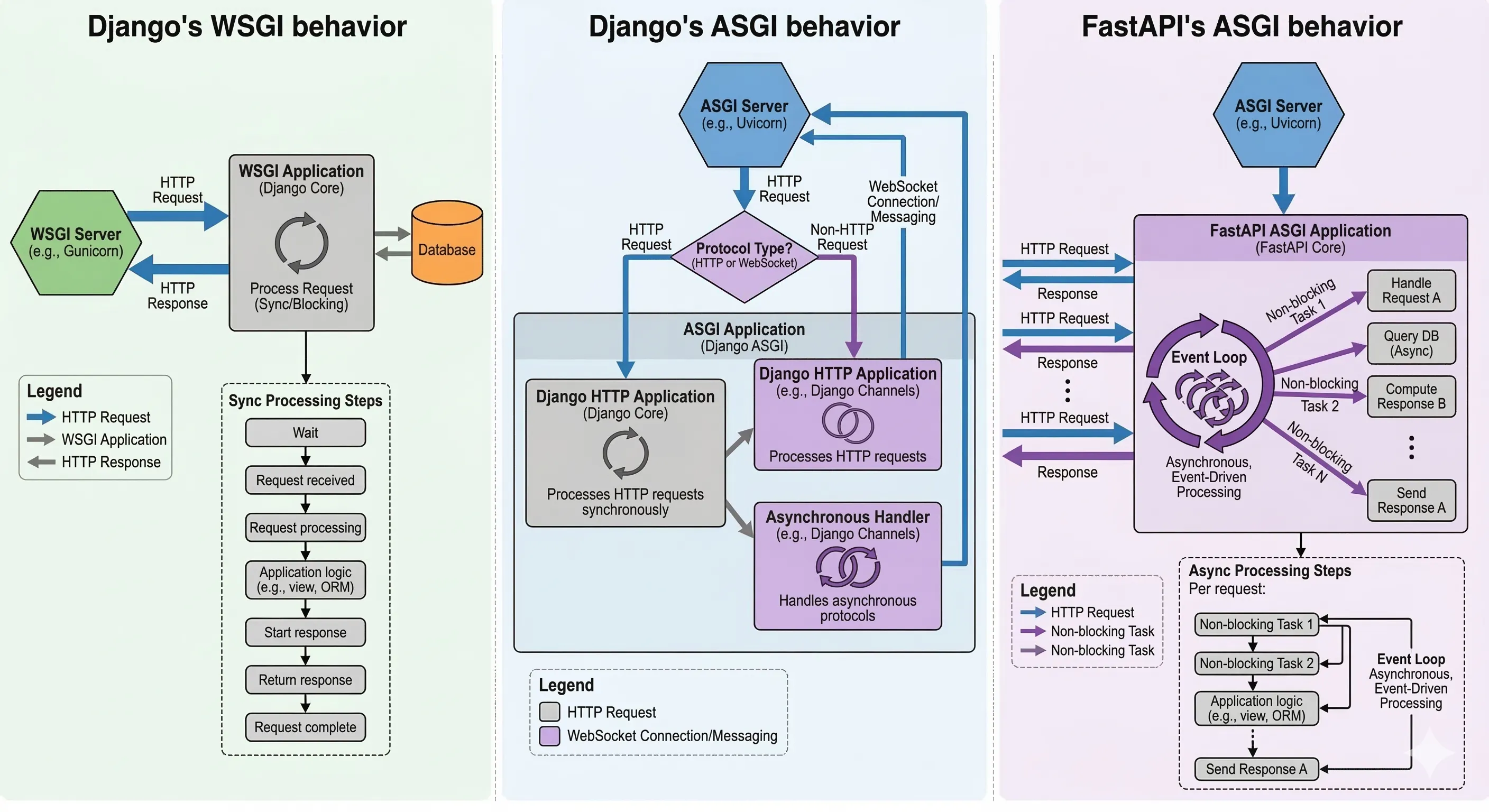
Quando o assíncrono realmente melhora o desempenho
O modelo assíncrono traz ganhos claros quando a carga é dominada por I/O, como muitos clientes aguardando respostas externas. Exemplos típicos incluem APIs com alto número de conexões simultâneas, WebSockets e streaming. Nesses casos, o event loop alterna tarefas enquanto aguardam rede ou disco, elevando a eficiência. A latência média cai e o consumo de memória por conexão tende a ser menor. O resultado é melhor uso de recursos com alto grau de concorrência.
Por outro lado, tarefas limitadas por CPU não se beneficiam apenas com código assíncrono. Cálculos pesados continuam ocupando o interpretador e podem exigir processos separados para escalar. Gargalos externos, como lentidão do banco ou de serviços terceiros, também limitam o ganho. Nesses cenários, a estratégia envolve paralelismo real com processos, cache e otimização de consultas. A escolha do modelo deve refletir o perfil dominante de carga da aplicação.
Implantação e escalabilidade em WSGI e ASGI
Em WSGI, escalar significa ajustar número de workers e threads, além de afinar timeouts e filas de conexão. O servidor HTTP frontal pode ficar responsável por estáticos e balanceamento, enquanto o servidor WSGI foca em Python. Monitoramento de memória por worker torna-se essencial, já que cada requisição ocupa um worker inteiro. Em picos, acrescentar processos aumenta vazão, mas com custo de memória. O padrão é estável e previsível, adequado a cargas clássicas.
Em ASGI, o ajuste considera quantidade de workers e a natureza do event loop, mantendo operações bloqueantes fora do loop. O servidor frontal continua útil para terminação TLS, compressão e cache, enquanto o ASGI gerencia concorrência por corrotinas. Serviços em tempo real ou streaming se beneficiam do suporte nativo a conexões duradouras. A relação entre workers e conexões simultâneas é mais elástica, desde que bibliotecas sejam não bloqueantes. O planejamento deve contemplar limites de thread pool e filas internas para manter a estabilidade.
Por que Django e FastAPI lidam de forma diferente com requisições
Django carrega um legado WSGI que favorece previsibilidade e um ecossistema maduro, adotando ASGI de modo compatível e gradual. A presença de componentes síncronos mantém a descrição de arquitetura híbrida adequada. FastAPI nasce na lógica assíncrona, priorizando concorrência de I/O e dependências não bloqueantes. Essa origem explica a sensação de leveza em serviços com muitas conexões simultâneas e uso de WebSockets. Em ambos os casos, a escolha do banco e dos drivers define se o caminho será totalmente assíncrono ou parcialmente híbrido.