
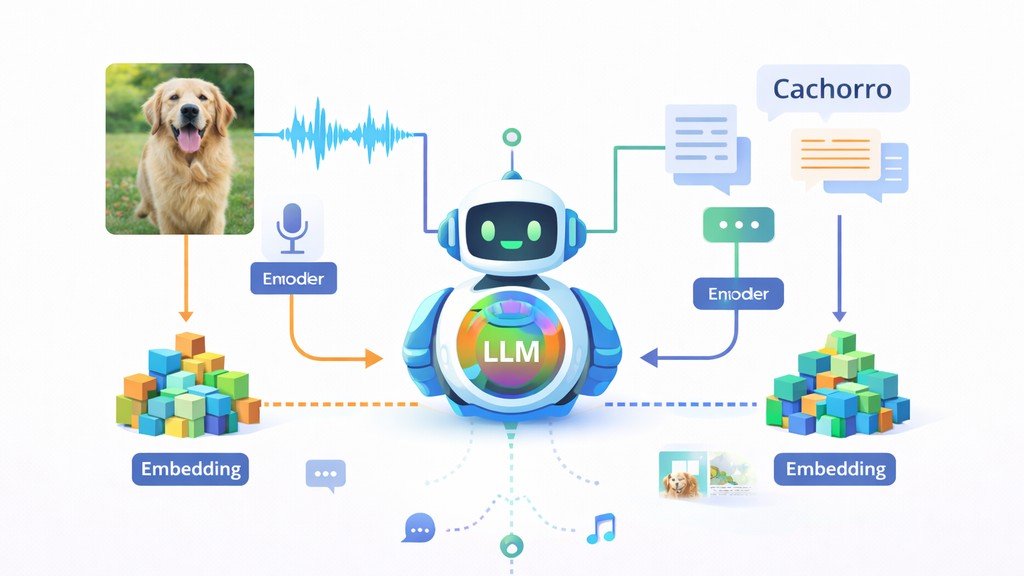
Modelos de linguagem multimodais (multimodal LLMs) são sistemas de IA capazes de lidar com diferentes tipos de dados, como texto, imagens e áudio, dentro de um mesmo processo de interpretação e resposta. A base desse avanço não depende de “um modelo para cada sentido”, mas de uma ideia matemática unificadora: transformar qualquer entrada em uma representação numérica comparável.
Essa unificação permite que conceitos iguais, vindos de formatos diferentes, fiquem próximos em um mesmo “mapa” matemático. Assim, a palavra escrita “cachorro”, um áudio com a palavra “cachorro” e uma foto de um cachorro podem ser tratados como variações do mesmo conceito. A partir disso, tornam-se possíveis tarefas como descrever uma imagem, relacionar som e texto, e responder perguntas que exigem combinar pistas visuais, auditivas e linguísticas.
Representação unificada: embeddings como “linguagem matemática compartilhada”
O elemento central é o embedding, que é um vetor (uma lista de números) usado para representar informações de forma compacta. Em vez de trabalhar diretamente com pixels, ondas sonoras ou caracteres, o modelo usa embeddings para posicionar cada entrada em um espaço matemático de muitas dimensões. Esse espaço pode ser entendido como um “mapa de significados”, onde itens semanticamente parecidos tendem a ficar próximos. Essa proximidade não é simbólica, mas geométrica: mede-se por similaridade entre vetores.
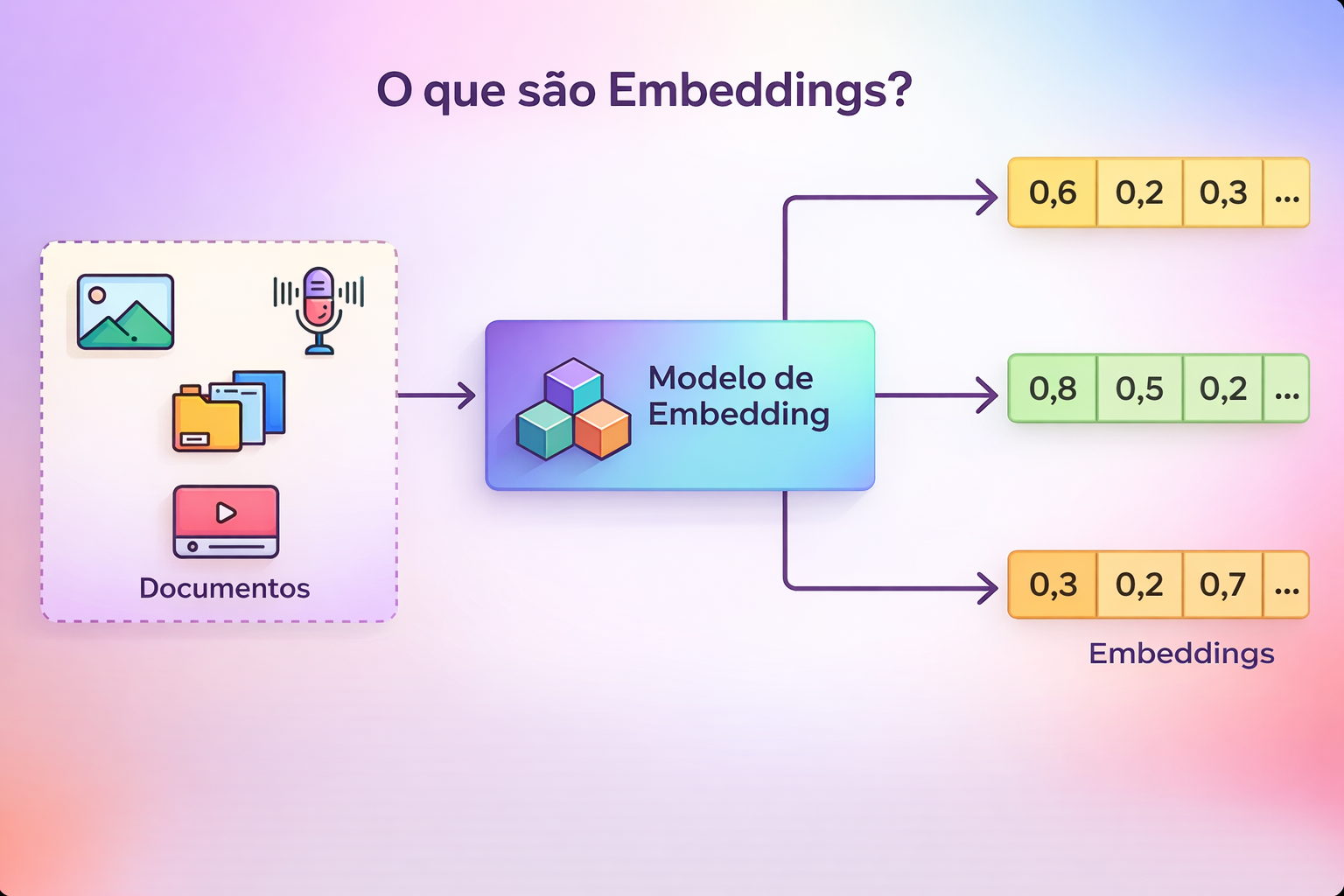
Em termos práticos, diferentes modalidades (texto, imagem, áudio) acabam convertidas no mesmo tipo de objeto matemático: vetores. Isso cria uma “ponte” conceitual entre dados muito distintos, como luz e som. A analogia mais comum é com o cérebro humano, que transforma estímulos diferentes em sinais neurais comparáveis. Nos LLMs multimodais, essa comparabilidade é a base para tratar tudo como uma sequência de tokens numéricos.
Exemplo concreto: foto, fala e texto representando o mesmo conceito
Um exemplo típico envolve o conceito “cachorro”. Uma fotografia de um cachorro, o áudio de alguém dizendo “cachorro” e a palavra “cachorro” escrita são entradas diferentes, mas podem resultar em embeddings próximos no espaço vetorial. Isso acontece quando o sistema aprendeu que essas entradas carregam o mesmo significado subjacente. O “estar próximo” é fundamental para permitir que um raciocínio feito com texto também funcione ao receber uma imagem.
Esse agrupamento em torno do mesmo conceito é frequentemente descrito como cluster (agrupamento) no espaço vetorial. Se o modelo vê uma foto de um golden retriever e também recebe a frase “o cachorro está feliz”, as representações podem se alinhar para sustentar a mesma interpretação. O modelo não “vê” o cachorro como um rótulo simples, mas como um conjunto de atributos aprendidos. Isso inclui pistas de contexto, como ambiente (praia, parque), postura e relação com outros elementos da cena.
Raciocínio cruzado entre modalidades (cross-modal reasoning)
Com uma representação compartilhada, surge o cross-modal reasoning, que é a capacidade de raciocinar conectando modalidades diferentes. Um som de latido, uma imagem de um cachorro e uma sentença sobre um cachorro podem reforçar o mesmo conceito interno. Esse reforço permite inferências que não dependem de um único tipo de dado. Em vez de “módulos separados”, o sistema pode usar uma mesma lógica de atenção e contexto para tudo.
Esse raciocínio cruzado é especialmente útil quando cada modalidade traz uma parte do significado. Uma imagem pode mostrar “um animal correndo”, enquanto o áudio pode indicar “latidos”, e o texto pode mencionar “parque”. Juntas, as pistas aumentam a confiança na interpretação e habilitam respostas mais coerentes. Essa coerência não vem de regras fixas, mas do alinhamento entre embeddings e do processamento unificado pelo transformador.
Arquitetura em três partes: encoders, projeção e backbone de linguagem
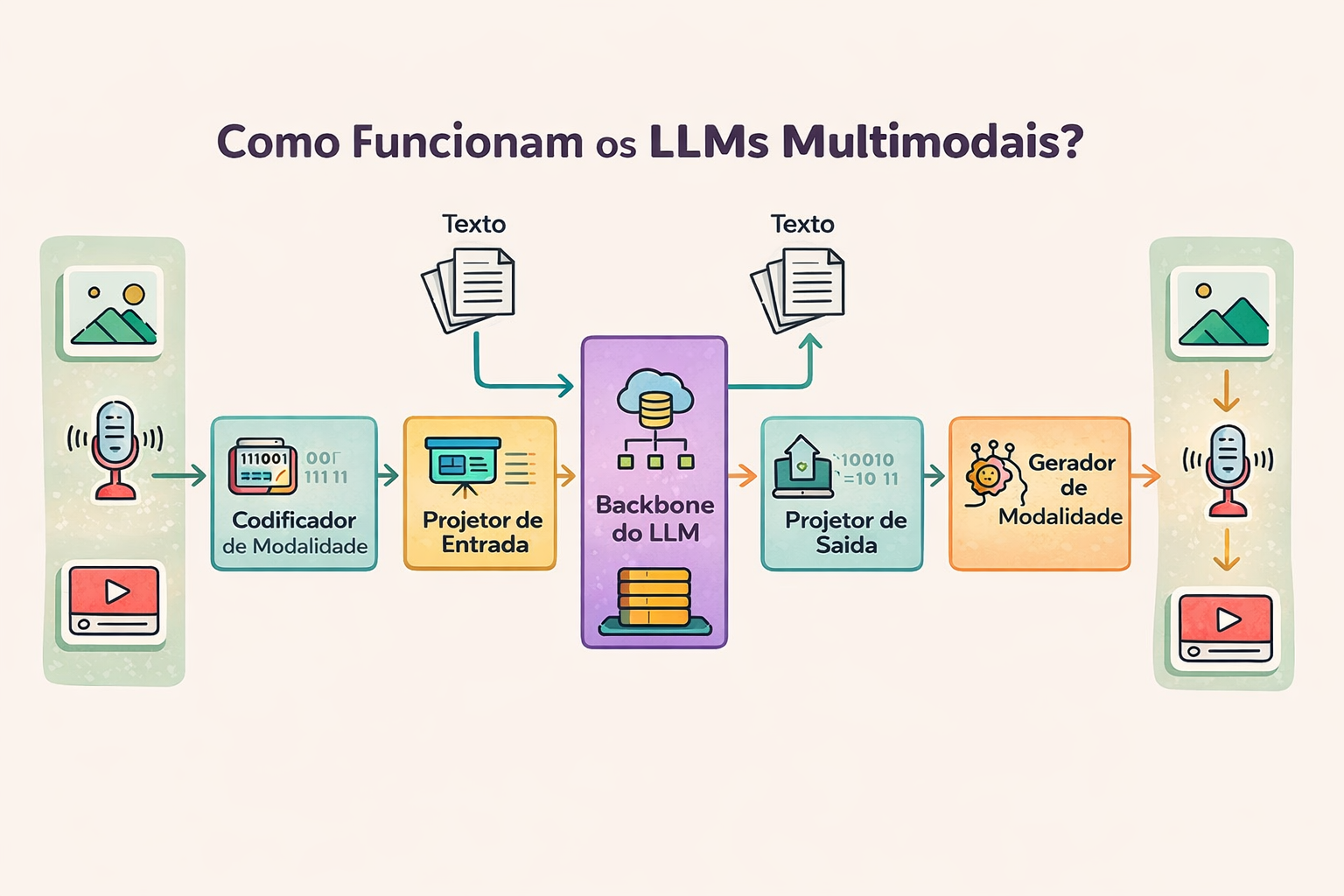
Modelos multimodais modernos costumam ser organizados em três blocos essenciais. O primeiro bloco transforma dados brutos de cada modalidade em vetores iniciais; o segundo alinha esses vetores ao espaço usado pelo modelo de linguagem; e o terceiro é o próprio modelo de linguagem, responsável por raciocinar e gerar saídas. Essa separação torna o sistema modular, mas ainda unificado no ponto central: a sequência final de tokens vetoriais. Cada bloco resolve um tipo de problema específico de representação.
Essa arquitetura também reflete restrições práticas. Imagens e áudio têm estruturas muito diferentes de texto, e precisam de pré-processamento especializado para virar tokens. Ao mesmo tempo, o LLM já é muito competente para raciocinar e produzir linguagem, então faz sentido reutilizá-lo como “núcleo”. A chave é traduzir visão e áudio para algo que o LLM consiga consumir como se fossem tokens textuais.
Encoders específicos de modalidade: convertendo dados brutos em vetores
O primeiro componente é o encoder (codificador) de cada modalidade, que transforma dados brutos em representações vetoriais iniciais. Em visão, é comum usar Vision Transformers (transformadores visuais), que tratam a imagem como uma sequência de partes, de modo semelhante a uma sentença. Em áudio, encoders costumam trabalhar sobre espectrogramas, que são representações 2D de como as frequências variam no tempo. Em todos os casos, o encoder é normalmente pré-treinado em grandes bases para aprender padrões gerais.
Esses encoders não “entendem” no sentido linguístico completo; eles extraem características úteis. Um encoder visual aprende contornos, texturas, padrões e relações espaciais. Um encoder de áudio aprende padrões de frequência e ritmo relacionados a fala, música ou ruídos. Esse estágio gera vetores ricos, mas ainda não necessariamente compatíveis com o “idioma interno” do LLM de texto.
Camadas de projeção: o tradutor entre espaços vetoriais
Mesmo que todos os componentes produzam vetores, esses vetores podem viver em espaços diferentes, com geometrias diferentes. A camada de projeção (projection layer) funciona como um tradutor matemático que pega o vetor do encoder visual ou de áudio e o transforma no formato esperado pelo LLM. Muitas vezes, esse tradutor é simples: uma transformação linear ou uma pequena rede neural com duas camadas. A simplicidade não reduz a importância, porque o alinhamento correto determina se “gato” em imagem fica próximo de “gato” em texto.
O ponto crítico é que o LLM foi treinado para operar num certo espaço de embeddings linguísticos. Se o vetor vindo da imagem não cair nesse espaço de maneira compatível, o LLM não consegue “conectar” o que vê com as palavras e conceitos que domina. A projeção resolve isso ajustando escala, orientação e distribuição dos vetores. Na prática, é a peça que viabiliza que patches de imagem e segmentos de áudio virem tokens comparáveis a tokens de texto.
Backbone de linguagem: o LLM como núcleo de raciocínio
O terceiro componente é o modelo de linguagem em si, frequentemente um transformador do tipo GPT ou LLaMA. Ele recebe uma sequência de tokens, mas esses tokens podem ter vindo de texto digitado, de patches de imagem ou de segmentos de áudio já projetados. O LLM processa tudo com a mesma arquitetura de atenção, como se fosse uma única sequência. Esse tratamento uniforme é parte do motivo pelo qual o sistema consegue combinar evidências de modalidades diferentes.
O transformador usa atenção (attention), um mecanismo que pondera quais tokens são mais relevantes para interpretar outros tokens. Assim, uma pergunta textual pode “puxar” informações dos tokens visuais correspondentes. O resultado é um raciocínio contextual que atravessa modalidades sem exigir um raciocinador separado para visão ou áudio. A saída costuma ser texto, mas o mesmo princípio pode ser estendido para geração em outras modalidades.
Como imagens viram tokens: patches, embeddings posicionais e atenção
Uma ideia decisiva para visão multimodal moderna foi tratar imagens como sentenças, dividindo-as em pequenos blocos chamados patches (pedaços). Em vez de analisar a imagem pixel a pixel, o modelo agrupa pixels em regiões fixas, como 16x16, e transforma cada região em um vetor. Isso reduz drasticamente o tamanho da entrada e torna possível aplicar transformadores, que esperam sequências. Com isso, cada patch passa a atuar como um “token visual”.
Uma imagem padrão de 224x224 pixels, ao ser dividida em patches 16x16, gera cerca de 196 patches. Cada patch é “achatado” (flatten), isto é, convertido de uma matriz 2D para um vetor 1D contendo intensidades de cor. Em seguida, são somados embeddings posicionais, que informam ao modelo onde aquele patch estava na imagem original. Sem essa informação, o modelo perderia noção de estrutura espacial, como “acima” e “à esquerda”.
Atenção em visão: formando contexto a partir de partes da imagem
Após virar uma sequência de tokens visuais, a imagem atravessa camadas transformadoras que aplicam atenção entre patches. A atenção permite que um patch “consulte” outros patches para formar contexto, em vez de ficar isolado. Um patch com parte de uma orelha pode ganhar significado ao se relacionar com patches do focinho, do corpo e do fundo. Esse encadeamento cria uma representação mais abstrata do conteúdo.
Com múltiplas camadas, a representação sai de padrões locais (cores e bordas) e vai para conceitos mais amplos. Uma combinação de patches pode representar “cachorro sentado”, enquanto o conjunto de patches do fundo pode representar “praia”. Essa integração permite que a saída não seja “pixels marrons”, mas um entendimento contextual como “golden retriever na areia perto do mar”. Esse tipo de abstração é essencial para responder perguntas sobre a cena, e não apenas descrevê-la de forma superficial.
CLIP e aprendizado contrastivo: alinhando imagem e texto sem rótulos clássicos
Outra inovação importante foi o CLIP, que treinou encoders de imagem e texto em pares imagem-legenda em larga escala. Em vez de depender de categorias fixas rotuladas manualmente, o modelo aprende a aproximar a imagem de sua descrição textual correta. O método central é o aprendizado contrastivo, que força o sistema a distinguir pares corretos de pares incorretos. Assim, uma foto de um cachorro se aproxima de “um cachorro no parque” e se afasta de “um prato de macarrão”.
No aprendizado contrastivo, cria-se um lote (batch) com várias imagens e várias frases correspondentes. O modelo calcula embeddings para todas as imagens e todos os textos, e mede similaridades. O objetivo é maximizar a similaridade nos pares corretos e minimizar nos incorretos, criando uma geometria semântica consistente. Isso gera encoders robustos, capazes de generalizar para descrições e objetos fora de um conjunto fechado de classes.
Como áudio vira algo tratável: do sinal contínuo ao mel-espectrograma
Áudio traz desafios próprios porque é um sinal contínuo no tempo, não uma sequência naturalmente discreta como palavras. Um áudio de 30 segundos a 16.000 Hz tem 480.000 amostras, o que seria impraticável para um transformador processar diretamente. A solução é converter o áudio em uma representação mais compacta, capturando padrões relevantes. A forma mais comum é o espectrograma, um “desenho” do som ao longo do tempo.
O passo a passo envolve fatiar o áudio em janelas pequenas e sobrepostas, como 25 milissegundos, preservando transições suaves. Em cada janela aplica-se a Transformada Rápida de Fourier (FFT), que decompõe o sinal em frequências presentes. Em seguida, as frequências são reamostradas na escala mel, que aproxima a sensibilidade do ouvido humano e dá mais detalhe nas baixas frequências. O resultado é um mapa 2D: tempo em um eixo, frequência em outro, e intensidade representando volume/energia.
Transformadores de espectrograma: tratando áudio como “imagem de som”
Com o mel-espectrograma pronto, o áudio passa a parecer uma imagem para fins computacionais. Isso permite reaproveitar ideias da visão, como dividir em patches e gerar tokens. O Audio Spectrogram Transformer segue essa lógica, construindo uma sequência de tokens a partir de regiões do espectrograma. Esses tokens carregam padrões acústicos associados a fonemas, palavras, pausas e ruídos.
Modelos como Whisper ficaram conhecidos por usar grandes volumes de dados para dominar essa transformação e a etapa seguinte de reconhecimento e compreensão. O ponto relevante é que o transformador não “escuta” diretamente; ele processa padrões visuais do espectrograma. A qualidade dessa representação depende de escolhas como tamanho de janela, taxa de amostragem e parametrização mel. Depois de convertido e tokenizado, o áudio entra no mesmo fluxo de projeção e backbone linguístico.
Treinamento em dois estágios: alinhamento de características e ajuste por instruções
O treinamento de um LLM multimodal costuma ocorrer em dois estágios, porque as necessidades são diferentes. No alinhamento de características (feature alignment), o objetivo é ensinar que representações equivalentes entre modalidades devem se corresponder. Nessa fase, o encoder de visão/áudio e o LLM geralmente ficam “congelados”, isto é, seus pesos não são atualizados. Apenas a camada de projeção é treinada para encaixar os vetores no espaço correto.
No segundo estágio, chamado ajuste por instruções multimodais (visual instruction tuning), o foco muda para seguir comandos e responder perguntas complexas. Alinhamento sozinho pode permitir descrições básicas, mas não garante habilidade de comparar, justificar ou inferir estados e relações. Nesse estágio, a projeção continua sendo treinada e parte do LLM também pode ser ajustada. Muitas abordagens usam técnicas de ajuste eficiente, que atualizam apenas subconjuntos de parâmetros para reduzir custo e risco de degradar capacidades.
Dados conversacionais e geração sintética: ampliando comportamentos de diálogo multimodal
Para ensinar comportamento de diálogo, os dados de treino passam a ter formato de instrução e resposta, frequentemente como conversas. Isso inclui perguntas sobre detalhes da imagem, comparações, explicações e raciocínios condicionais. Um desafio é que criar esse tipo de dado rotulado é caro e demorado. Por isso, tornou-se comum gerar dados sintéticos de alta qualidade, onde um modelo forte produz diálogos plausíveis a partir de descrições textuais de imagens.
Esse processo é uma forma de destilação, isto é, transferência de comportamentos de raciocínio de um sistema mais capaz para outro. O objetivo não é copiar imagens, mas transferir padrões de resposta: justificar, reconhecer ambiguidades e manter consistência. Com dados sintéticos bem construídos, o modelo aprende a ir além da legenda (“há um cachorro”) e sustentar respostas mais ricas (“o cachorro parece feliz porque está com a boca aberta e postura relaxada”). Esse treinamento torna o sistema mais útil em tarefas que exigem interpretação e não apenas identificação.
Por que a multimodalidade funciona e o que ela consolida?
LLMs multimodais funcionam porque colocam texto, imagem e áudio dentro de uma mesma linguagem matemática baseada em vetores de embedding. Ao alinhar essas representações em um espaço compartilhado, um único transformador consegue aplicar atenção, contexto e geração de linguagem sobre entradas de diferentes origens. A arquitetura em três partes — encoders específicos, camada de projeção e backbone de linguagem — organiza esse processo de forma prática e escalável. Inovações como Vision Transformers, aprendizado contrastivo no estilo CLIP e espectrogramas para áudio consolidam o caminho para integrar modalidades sem depender de múltiplos “cérebros” separados.
O resultado é um sistema capaz de interpretar conceitos como entidades abstratas, independentemente de estarem escritos, falados ou visíveis. Esse tipo de integração sustenta o raciocínio cruzado entre modalidades e torna possível responder com consistência em tarefas que combinam percepção e linguagem. A multimodalidade, nesse sentido, não é um conjunto de truques isolados, mas uma consequência direta de uma representação unificada e de um mecanismo de atenção que generaliza bem para sequências. Com isso, fecha-se um ciclo completo: dados brutos são codificados, alinhados, processados e transformados em respostas coerentes dentro de um mesmo núcleo de raciocínio.