
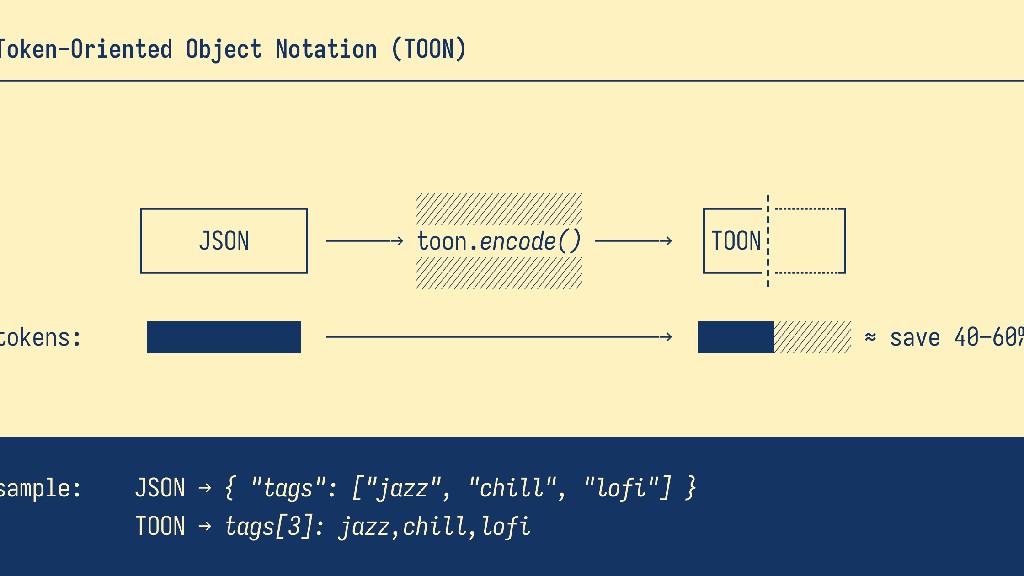
O formato TOON — sigla para Token‑Oriented Object Notation — representa uma inovação no modo como dados estruturados são transmitidos para modelos de linguagem artificial. Criado com foco em eficiência e legibilidade, ele busca reduzir drasticamente o número de tokens consumidos quando comparado ao formato JSON tradicional. Essa economia de tokens reflete diretamente em menor custo computacional, respostas mais rápidas e maior capacidade de contexto para as inteligências artificiais que processam grandes volumes de informação.
Diferente dos formatos convencionais, o TOON combina vantagens do CSV e do YAML, resultando em uma representação compacta, hierárquica e otimizada para modelagem de linguagem. Ele permite expressar estruturas complexas com menor redundância e mínima pontuação, tornando-se particularmente vantajoso quando lida com conjuntos de dados uniformes e grandes coleções de objetos semelhantes.
Motivações para o surgimento do TOON
O JSON consolidou-se como o padrão mais popular para troca de dados na web e em sistemas de inteligência artificial. No entanto, seu formato é altamente verboso e exige a repetição de chaves em cada item de uma lista, o que aumenta consideravelmente o custo de tokens para modelos de linguagem. Em contextos onde cada token é cobrado, como em GPTs, essa redundância representa um grande desperdício. O TOON foi criado para superar essa limitação ao remover repetições desnecessárias e empregar estruturas mais compactas.
O formato também nasceu de uma observação prática: modelos de linguagem têm desempenho melhor quando o dado fornecido é consistente e previsível. Por isso, o TOON foi desenhado para fornecer pistas estruturais claras, como o número de elementos e os nomes dos campos em arrays, reduzindo erros de interpretação e aumentando a precisão das inferências.
Princípios de funcionamento
O TOON adota um estilo baseado em indentação em vez de chaves e colchetes, inspirando-se parcialmente no YAML para representar estruturas hierárquicas. Arrays exibem a quantidade de elementos diretamente nos colchetes — por exemplo, items[2] — informando ao modelo o tamanho esperado do conjunto. Além disso, em vez de repetir chaves para cada objeto, o formato permite declarar o cabeçalho uma única vez e listar as linhas correspondentes.
Essa abordagem reduz cerca de 40 a 60% dos tokens em comparação com JSON. O TOON também emprega um conjunto mínimo de sinais de pontuação, citando valores de texto apenas quando necessário, o que ajuda a conservar tokens sem comprometer a legibilidade humana.
Exemplo comparativo entre JSON e TOON
O mesmo conjunto de dados pode ser expresso de maneira muito mais compacta no novo formato. O exemplo a seguir mostra as representações equivalentes:
{
"users": [
{ "id": 1, "name": "Alice", "role": "admin" },
{ "id": 2, "name": "Bob", "role": "user" }
]
}No formato TOON, essa estrutura torna-se:
users[2]{id,name,role}:
1,Alice,admin
2,Bob,userO ganho é evidente: além de eliminar chaves e aspas redundantes, o formato informa claramente o número de registros e o nome dos campos, simplificando a análise por parte do modelo.
Tipos de estruturas compatíveis
O TOON suporta diferentes formas de representação conforme a natureza dos dados. Objetos simples são codificados como pares chave: valor; estruturas aninhadas usam indentação para indicar hierarquia; já as listas podem assumir três configurações principais: listas de valores primitivos, listas mistas e listas de objetos homogêneos.
Para objetos com o mesmo conjunto de campos, o formato tabular é utilizado. Nele, as chaves aparecem apenas uma vez no cabeçalho e as linhas seguintes contêm apenas os valores. Quando os objetos diferem em estrutura ou possuem campos adicionais, o TOON recorre à forma de lista, semelhante ao YAML.
Arrays e delimitação de dados
Em arrays, o TOON permite delimitar valores por vírgula, tabulação ou barra vertical. Cada delimitador possui vantagens específicas. As vírgulas são o padrão e funcionam bem na maioria dos contextos, enquanto o tab costuma reduzir ainda mais o consumo de tokens, pois raramente aparece em texto comum. Já o pipe oferece uma alternativa intermediária, útil para dados com campos que já contêm vírgulas.
A definição explícita do delimitador na linha de cabeçalho torna o formato autodescritivo. Por exemplo, um cabeçalho com tabulação explicita o uso do caractere “\t”: items[2 ]{sku name qty price}:, seguido de suas linhas correspondentes.
Regras de formatação e indentação
Toda linha usa dois espaços por nível de aninhamento, sem espaços ou quebras desnecessárias no final. Objetos simples mantêm o formato chave: valor, enquanto objetos vazios apenas exibem a chave com dois-pontos. Arrays incluem a contagem de itens entre colchetes, e listas começam com hifens para denotar cada item.
As aspas só são utilizadas quando um valor contém caracteres especiais, espaços à esquerda ou à direita, ou quando o conteúdo pode ser confundido com valores booleanos ou numéricos. Isso garante parseamento previsível com mínima sobrecarga de tokens.
Economia comprovada de tokens
Testes realizados com codificadores modernos, como o o200k_base, demonstram economias expressivas. Dados analíticos diários, por exemplo, consumiram 4.507 tokens no formato TOON contra 10.977 em JSON — uma redução de quase 59%. Em outros experimentos, o ganho superou 40% em repositórios GitHub e 55% em comparações com XML. Esses resultados reforçam a eficiência prática do formato em contextos de custo elevado por token.
Além disso, estudos de precisão mostraram que o TOON mantém a integridade semântica dos dados. Durante tarefas de recuperação em diferentes modelos de linguagem, alcançou taxas de acerto superiores a 99% em alguns cenários, superando alternativas tradicionais como YAML, CSV e JSON.
Uso prático em aplicações com IA
A biblioteca oficial do TOON pode ser instalada por gerenciadores como npm, yarn ou pnpm. O método principal, encode(), converte qualquer dado compatível com JSON em formato TOON. Esse método ainda aceita opções para ajustar o espaçamento da indentação, o delimitador utilizado e a presença de marcadores de comprimento em arrays.
import { encode } from '@byjohann/toon'
const dados = {
user: {
id: 123,
name: 'Ada',
tags: ['reading', 'gaming'],
active: true
}
}
console.log(encode(dados))O resultado obtido é o seguinte:
user:
id: 123
name: Ada
tags[2]: reading,gaming
active: trueBenefícios e limitações
O TOON apresenta diversas vantagens, como a redução de custo em requisições para modelos de linguagem, estrutura autorreferente, formatação determinística e melhor desempenho em tabelas uniformes. Também preserva a ordem das chaves e minimiza erros de geração ao ser utilizado em saídas esperadas de IA.
Contudo, o formato é menos indicado para dados fortemente aninhados ou mistos, pois nesses casos perde parte da compactação esperada. Além disso, não substitui o JSON em APIs ou bancos de dados, sendo voltado exclusivamente para comunicação eficiente entre humanos e modelos de linguagem em tarefas de processamento de texto.
Síntese do papel do TOON
Com base em princípios de economia e clareza, o TOON redefine a maneira como dados estruturados são formatados para IA. A simplicidade sintática, combinada à redução drástica de tokens, o posiciona como uma ferramenta estratégica para o futuro do processamento eficiente de grandes linguagens. Sua popularidade crescente demonstra o valor de unir legibilidade humana e otimização técnica em um único padrão.
Repositório oficial: github.com/johannschopplich/toon